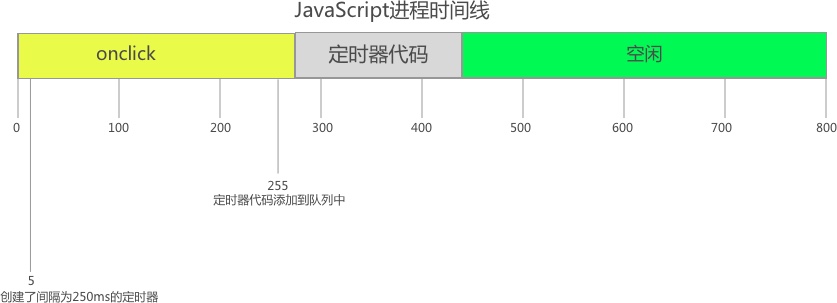
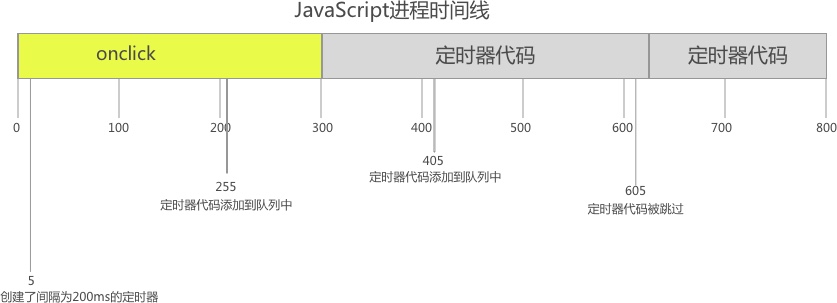
栈(stack)
栈是为执行线程而在内存中临时留出的空间。当一个程序被调用,栈顶的块被保留下来,作为局部变量和一些临时的数据。当那个程序返回后,这个块被释放了,并且能够在下次一个程序被调用的时候被使用。栈总是以后进先出(LIFO)的顺序保存数据,最近被保留的块总是最先被释放的。这使得记录栈很容易;释放一个块仅仅只是调整了一个指针。
堆(heapd)
堆是为了动态分配而在内存中留出的。不像栈,在堆中没有固定的模式去分配和重新分配块;你能够在任何时刻分配一个块和释放一个块。这使得在给定时间内去追踪堆的哪部分是被分配了的和是被释放了的变得十分复杂;有许多可用的自定义的堆分配器,他们可以根据不同的使用模式来对堆的表现形式进行调整。
每个线程都有一个栈,但在一个应用中一般只有一个堆。